
O modelowaniu atrybucji mówiono różne rzeczy. Miało być panaceum, jedynym źródłem prawdy i odpowiedzią na pytania o alokację budżetów reklamowych. Powstawały nowe narzędzia i metody analizy atrybucji, tworzono wyszukane modele.
Później pojawiły się głosy, że atrybucji już nie ma i niespecjalnie jest czym się już zajmować. Meta wyłączyła swoje narzędzie Facebook Attribution, a w Google Ads i Analytics zredukowano liczbę dostępnych modeli. Ale jest jednak jedna rzecz, którą trzeba wyraźnie powiedzieć.
Atrybucja jest jak pogoda. Nie może jej nie być. Jest zawsze.
Niezależnie od jakości danych i dostępnych narzędzi, atrybucja konwersji i przychodów będzie zawsze jednym z podstawowych wyzwań każdego marketera.
W roku 2024 w Google Analytics wprowadzono zmianę terminologii i dotychczasowe konwersje w Analytics zostały nazwane kluczowymi zdarzeniami. W tym artykule użycie słowa „konwersja” (w ogólnym znaczeniu) nie zawsze będzie zgodne z terminologią Analytics.
Czym jest modelowanie atrybucji?
Modelowanie atrybucji to przypisywanie poszczególnym działaniom marketingowym udziału w uzyskiwanym przez firmę przychodzie. W analityce marketingu cyfrowego sprowadza się ona często do raportowania konwersji i przychodów generowanych przez kampanie reklamowe.
Mimo upływu lat, najczęściej stosowane, standardowe modele oceny skuteczności działań marketingowych online przypisują całość zasług w doprowadzeniu do konwersji ostatniemu kliknięciu w reklamę lub inny link prowadzący do strony internetowej. Wcześniejsze wizyty użytkownika na stronie są ignorowane, choć nierzadko zdarza się, że użytkownicy odwiedzają stronę wiele razy z różnych źródeł zanim dokonają konwersji:

Systemy śledzenia konwersji systemów reklamowych (np. Google Ads, Meta Ads) przypisują konwersje tylko reklamom danego systemu. Nie ma znaczenia, czy użytkownik również wchodził na stronę z innych źródeł, czy nie.
Jeśli nasz klient kliknie reklamę Google Ads, następnie kliknie reklamę na Facebooku, po czym odwiedzi stronę przez link w artykule na portalu internetowym, by po kilku dniach wejść bezpośrednio i dokonać zakupu to:
- system Google Ads wskaże, że konwersja pochodzi z reklamy Google Ads,
- śledzenie konwersji reklam w Meta przypisze ją reklamie na Facebooku,
- raport pozyskania ruchu Google Analytics jako źródło tej konwersji wskaże odesłanie (referral) z domeny portalu.
Co więcej – każdy z tych raportów będzie „twierdził”, że dane źródło w 100% odpowiada za doprowadzenie do konwersji.
Użytkownicy, którzy konwertują przy pierwszej wizycie na stronie stanowią tylko pewną część konwersji. Będzie ona tym mniejsza, im poważniejszą decyzję dana konwersja stanowi. Jeśli konwersją jest np. pobranie pliku, to będzie ona przeciętnie wymagała mniej wizyt, niż subskrypcja newslettera.
Gdy leadem jest zapytanie zakupowe, konwersji przy pierwszej wizycie będzie jeszcze mniej. Jeśli konwersją jest zakup i opłacenie transakcji, to liczba konwersji, które wymagały więcej niż jednej wizyty będzie większa – tym bardziej, im bardziej wartościowy jest kupowany produkt.
Na przeciętną liczbę wizyt przed zakupem wpływać też będą inne czynniki, takie jak siła marki, zaufanie do niej i lojalność klientów, a także to, na ile dany produkt jest unikalny i jaka panuje na rynku konkurencja – co może skłaniać użytkowników do szukania opinii i porównywania ofert.
W branży e-commerce użytkownicy dokonują przeciętnie kilku wizyt przed transakcją, a wizyty te często pochodzą z różnych źródeł. Mówimy o konwersjach wielokanałowych – za doprowadzenie do transakcji odpowiada kilka różnych, nachodzących na siebie kanałów marketingowych:
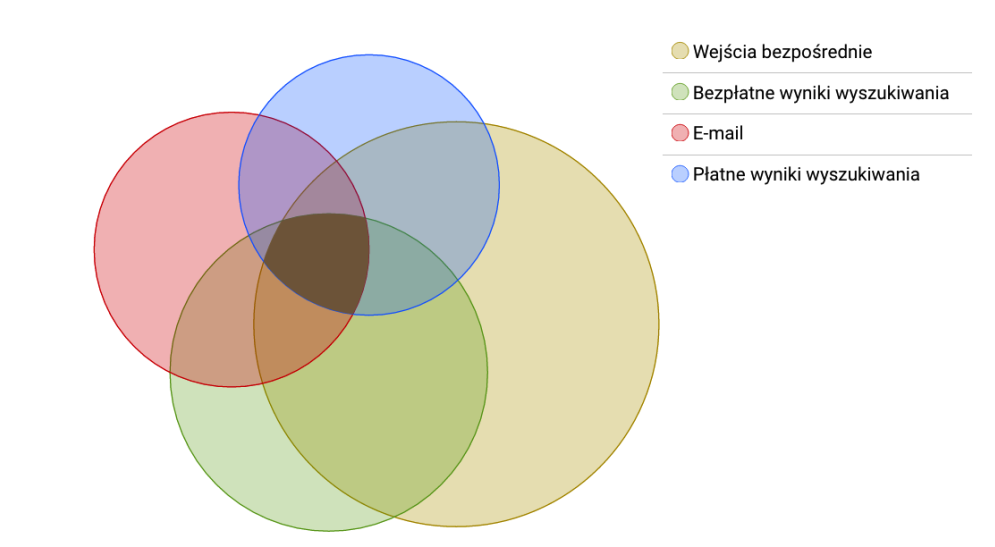
Jest oczywiste, że jeśli kilka systemów śledzenia konwersji przypisuje sobie 100% udział w doprowadzeniu do danej transakcji, to nie mogą one wszystkie mieć racji.
Przypisywanie całości zasług w doprowadzeniu do konwersji jednemu z nakładających się na siebie kanałów jest co do zasady nieprawidłowe, a podejmowane na tej podstawie decyzje o alokacji budżetów reklamowych na poszczególne kanały mogą być obarczone błędem.
Czasem zmiana modelu atrybucji niewiele zmieni
Błąd wynikający z przypisania całości udziału w konwersji jednej interakcji nie zawsze będzie duży. W przypadku nachodzących na siebie kanałów, efekt przenikania się źródeł konwersji może się wzajemnie znosić, skutkiem czego może się zdarzyć, że model przypisujący 100% udziału w konwersji do ostatniego kliknięcia nie będzie się istotnie różnił od alternatywnych modeli.
Przykładowo załóżmy, że mamy następujące ścieżki konwersji:
| Ścieżka atrybucji | Liczba konwersji | |
|---|---|---|
| 1. | Google > Google | 10 |
| 2. | Google > Facebook | 10 |
| 3. | Facebook > Google | 10 |
| 4. | Facebook > Facebook | 10 |
| Łącznie | 40 |
W takim przypadku przypisanie konwersji do źródeł w różnych modelach atrybucji będzie wyglądać następująco:
| Źródło | Last click | First click | Linear | Time decay |
|---|---|---|---|---|
| 20 | 20 | 20 | 20 | |
| 20 | 20 | 20 | 20 | |
| Łącznie | 40 | 40 | 40 | 40 |
Jak widać, każdy z tych zupełnie różnych modeli atrybucji pokazuje dokładnie to samo!
W realnym świecie rozkład ścieżek rzecz jasna nie będzie aż tak równomierny, ale powyższy przykład pokazuje, w jaki sposób wpływ poszczególnych ścieżek atrybucji na łączny wynik atrybucji może się wzajemnie znosić i spłaszczać różnice między różnymi modelami. Zob. też artykuł o porównaniu modeli atrybucji.
Często jednak różnice pomiędzy poszczególnymi modelami mogą być bardzo istotne i skutkować nawet wielokrotnym niedoszacowaniem lub przeszacowaniem opłacalności danego źródła ruchu.
Modelowanie atrybucji pomaga określić znaczenie poszczególnych źródeł ruchu i faktyczną wartość każdego z pokrywających się źródeł ruchu prowadzących do konwersji.
Dlaczego modelowanie atrybucji ma znaczenie?
Marketing wielokanałowy jest grą zespołową i jak w każdej profesjonalnej dyscyplinie grupowej, znaczenie ma dobór zawodników oraz ich właściwe wynagradzanie. Właściwe, czyli odpowiadające ich wpływowi na sukces drużyny.
W piłce nożnej jednym z kluczowych wskaźników jest liczba zdobytych bramek. Premię za wygrany mecz można by było więc rozdzielić pomiędzy strzelców goli. Zawodnik, który zdobył więcej bramek, otrzymałby premię wielokrotną:
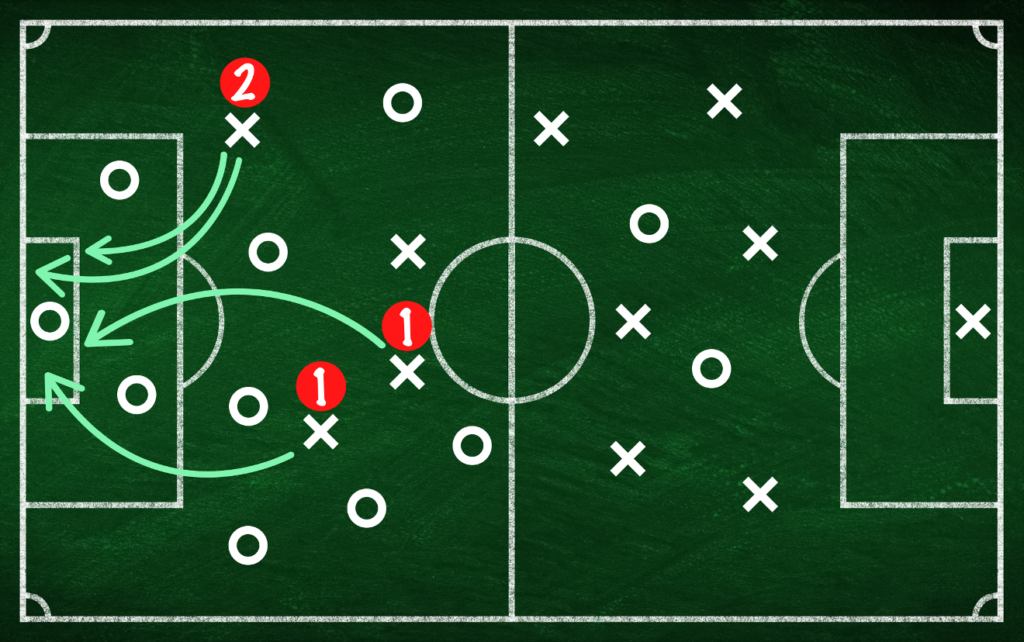
Rzecz jednak w tym, że na wynik meczu składa się gra wszystkich członków zespołu. W takim ujęciu zawodnicy grający w obronie lub w środku pola uznawani będą za mało produktywnych, a bramkarz, który niezwykle rzadko ma okazję strzelić bramkę – będzie w zasadzie zbędnym kosztem.
Można by było zasady wynagradzania zmodyfikować i część wynagrodzenia przeznaczyć dla tych graczy, którzy asystowali przy bramkach:
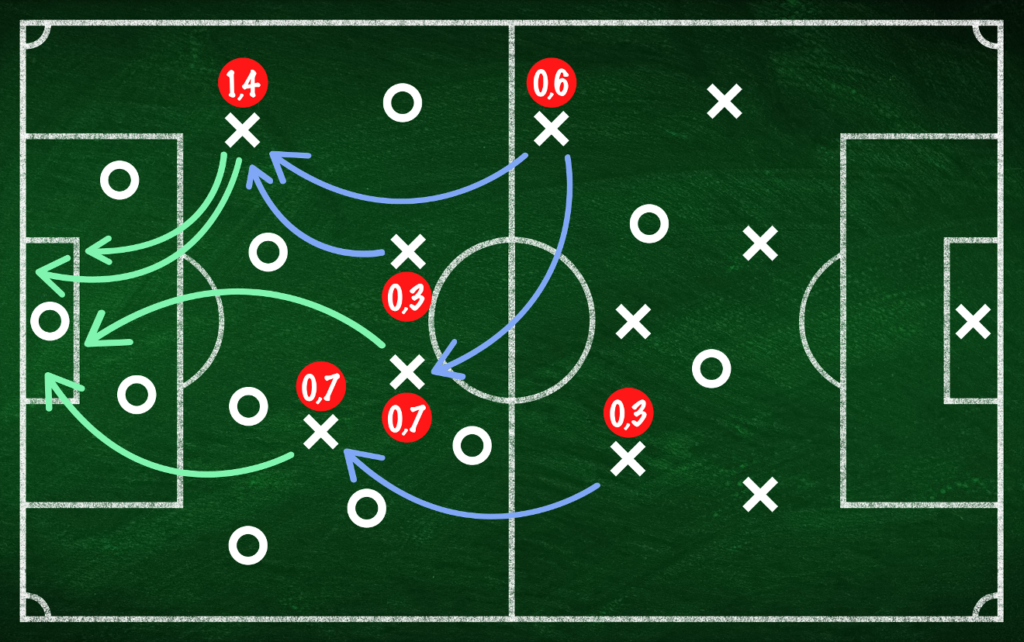
Ale również ta metoda wydaje się dyskryminować zawodników grających w obronie. Tak naprawdę, udział w nagrodzie powinni mieć wszyscy gracze. Pytanie, jaki?
Jeśli odpowiedź na to pytanie jest taka trudna, to dlaczego w takim razie nie wynagradzać wszystkich zawodników po równo? Taka metoda jest prosta, czytelna i można powiedzieć – sprawiedliwa.
Tyle że nie wszyscy zawodnicy są tak samo wartościowi, a napastnicy nie bez powodu są gwiazdami i filarami drużyny. Tak więc optymalna, najlepsza, najbardziej efektywna metoda wynagradzania, która pozwoli zebrać skład zespołu i zmotywować zawodników jest bardziej złożona.
Podobna sytuacja może mieć miejsce w przedsiębiorstwach, gdzie często zdarza się, że najwyższe premie za wynik otrzymują sprzedawcy. Rezultat ich pracy jest zresztą namacalny – to przychód ze sprzedaży na rzecz obsługiwanych przez nich klientów.

Rzecz w tym, że jeśli produkt jest słabej jakości i ma złą opinię na rynku, klienci go nie poszukują, a logistyka kuleje – to nawet najlepsi sprzedawcy nie będą w stanie wygenerować wyniku. Dlatego trzeba zadbać o całość organizacji i właściwie wynagradzać wszystkich pracowników.

Świetne produkty sprzedają się same, więc paradoksalnie, obniżenie procentowej prowizji dla sprzedawców i wsparcie zespołu może spowodować wzrost wynagrodzenia sprzedawców, bo zaczną sprzedawać więcej, szybciej i łatwiej.
Wreszcie, właściwe wynagradzanie oznacza, że nie możemy marnować budżetu na tych członków zespołu, którzy nie wnoszą wkładu w wynik lub ich wyniki są iluzoryczne. Sytuację taką opisuje historia z tej animacji:
Chyba nie trzeba dłużej przekonywać, że właściwa ocena efektywności i odpowiednie wynagradzanie członków zespołu ma istotny wpływ na osiągane wyniki. Marketing nie będzie tu wyjątkiem.
W czym pomoże nam modelowanie atrybucji, a w czym nie?
Modelowanie atrybucji nie jest pomiarem wpływu kampanii na przyrost sprzedaży, lecz metodą analizy dostępnych danych pochodzących ze śledzenia konwersji.
Śledzenie konwersji, które raportuje wyłącznie korelację miedzy kliknięciami i innym interakcjami a konwersjami, nie dostarcza danych umożliwiających określenie stopnia związku przyczynowo-skutkowego między nimi.
Prawdziwy pomiar efektów kampanii jest możliwy wyłącznie w ramach testu z grupą kontrolną (conversion lift), co wymaga ingerencji w wyświetlanie reklam (zob. też artykuł o modelu atrybucji opartym o dane).
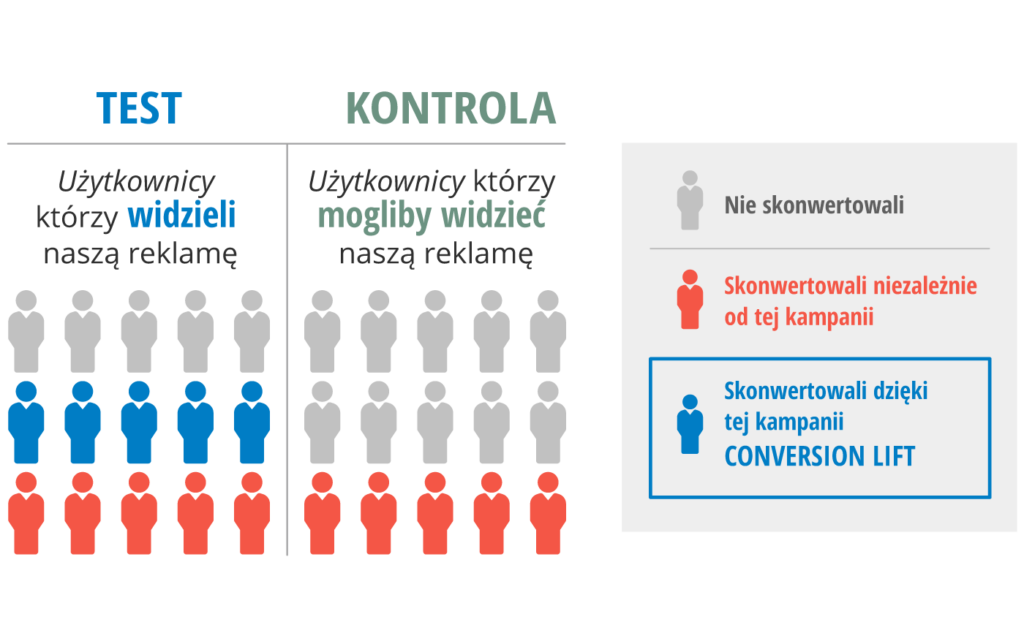
Warto zwrócić uwagę na kwestię istotności statystycznej wyników takiego testu, która nawet w przypadku dużych stron internetowych będzie osiągalna wyłącznie dla pomiarów przyrostu konwersji generowanego przez najistotniejsze kanały reklamowe (bez granularnego podziału).
Nawet gdy systemy reklamowe zaczną modelować atrybucję randomizowanymi testami z grupą kontrolną, to będą to mogły zrobić wyłącznie w ramach własnego systemu. A jeśli i tę barierę udałoby się kiedyś pokonać (czytaj: wszyscy uczestnicy rynku martech, w tym Google, Meta, Microsoft, Amazon itd. zaczną się swobodnie wymieniać danymi, co z wielu powodów jest mało prawdopodobne), to pewne źródła wciąż pozostaną niezależne (np. bezpłatne wyniki wyszukiwania, odesłania ze stron zewnętrznych – których dla potrzeb testu nie będzie dało się zablokować).
Dlatego przeprowadzenie testu polegającego na wyłączeniu każdego źródła ruchu dla testowanej grupy użytkowników, a tym samym, zmierzenie skuteczności wszystkich kanałów marketingowych – w praktyce najprawdopodobniej nie będzie nigdy możliwe.
Trzeba też pamiętać, że systemy śledzące, takie jak Google Analytics – nie dostarczają nam 100% informacji na temat źródeł ruchu, a modelowanie atrybucji z użyciem tych narzędzi ogranicza się tylko do tych danych, które są w nich dostępne.
Oto kilka przyczyn niekompletności danych:
- Wiele wizyt nie ma zidentyfikowanych źródeł ruchu. W Google Analytics takie wizyty będą pojawiały się jako wizyty bezpośrednie. Wizyta bezpośrednia to nie tylko wpisanie adresu strony do przeglądarki czy kliknięcie zakładki z ulubionymi linkami (zob. artykuł o wizytach bezpośrednich). Wiele programów blokujących śledzenie usuwa tagi śledzące, co dodatkowo zwiększa liczbę wizyt identyfikowanych jako bezpośrednie.
- Systemy śledzenia konwersji mierzą głównie źródła online, a więc użytkownicy, którzy weszli na stronę po obejrzeniu reklamy w telewizji, billboardu, ulotki lub reklamy prasowej, czy też po odwiedzeniu tradycyjnego sklepu w fizycznej lokalizacji – nie będą mieli zidentyfikowanych tych punktów styku.
- Śledzenie innych interakcji niż kliknięcia jest utrudnione. O ile kliknięcie umożliwia przesłanie identyfikatora i przetwarzanie danych w kontekście 1st party, to śledzenie wyświetleń wymaga rozwiązań przekazujących dane między stronami. Cross-site tracking jest obecnie jest na cenzurowanym, a firmy technologiczne starają się temu przeciwdziałać. Niektóre media w ogóle nie pozwalają na umieszczenie tagu wyświetlenia, gdyż nie chcą na masową skalę udostępniać danych o korzystaniu użytkowników z serwisu.
Mimo tych ograniczeń, modelowanie atrybucji może dostarczyć wielu cennych informacji i pozwolić zaoszczędzić i/lub zarobić sporo pieniędzy. Nawet jeśli uzyskane odpowiedzi nie będą stuprocentowe, będzie nam łatwiej odpowiedzieć na pytania, takie jak:
- Na ile poszczególne źródła ruchu wpływają na konwersje i jaka jest ich wartość w porównaniu z ponoszonymi na nie wydatkami?
- W jakim stopniu źródła ruchu nachodzą na siebie?
- Czy nachodzące na siebie kanały wspierają się, czy się kanibalizują?
- Na ile zwiększenie wydatków, ich zmniejszenie lub rezygnacja z danego źródła ruchu powinny wpłynąć na zmianę w przychodach i ponoszonych wydatkach?
- W które źródła ruchu należy zainwestować więcej, w które mniej, a z których być może zupełnie zrezygnować?
Modelowanie atrybucji w praktyce
W kolejnych artykułach na ten temat spróbujemy się przyjrzeć szeregowi praktycznych zagadnień związanych z modelowaniem atrybucji.
Zainteresowanych doradztwem w zakresie modelowania atrybucji zapraszamy do kontaktu z nami.
Następny artykuł (cz. 2): Grupy kanałów
Warto przeczytać: Przewodnik po atrybucji w Google Analytics
Pozostałe artykuły o modelowaniu atrybucji:
Terminologia (cz. 3)
Okno konwersji (okres ważności) (cz. 4)
Wizyty bezpośrednie (direct) i modele niebezpośrednie (cz. 5.)
Porównanie modeli atrybucji (cz. 6)
Modele single-touch (cz. 7)
Modele multi-touch (cz. 8)
Model oparty o dane (Data-driven) (cz. 9)
Wartość Shapleya – cz. 10)
Łańcuchy Markowa (cz.11)
Wspomaganie czy kanibalizacja – (cz. 12)
Konwersje wspomagane (cz. 13)


