
Poprzedni artykuł (cz. 8): Modele multi-touch
Google udostępnia algorytmiczny model atrybucji (model oparty o dane, data-driven attribution) w systemach Google Ads i Analytics, a także w Campaign Managerze.
W modelu tym podział konwersji między interakcje obliczany jest według indywidualnej reguły, która w dodatku zmienia się w czasie na bazie danych o konwersjach danej strony, z wykorzystaniem mechanizmów uczenia maszynowego i sztucznej inteligencji.
Algorytm opiera się o analizę ścieżek konwertujących i niekonwertujących, dla których porównywane jest prawdopodobieństwo konwersji i na tej podstawie określana jest cząstkowa wartość danego kanału.
Przykładowo, załóżmy, że dla użytkownika, który wszedł na stronę z wyszukiwarki (search), a następnie otrzymał newsletter (e-mail), prawdopodobieństwo konwersji wynosi 2%. Ponadto, jeżeli na takiej ścieżce pojawi się dodatkowo reklama display, to prawdopodobieństwo wynosi 3%.
Na tej podstawie algorytm szacuje, że dzięki kanałowi display prawdopodobieństwo konwersji rośnie o 50% (z 2% na 3%).
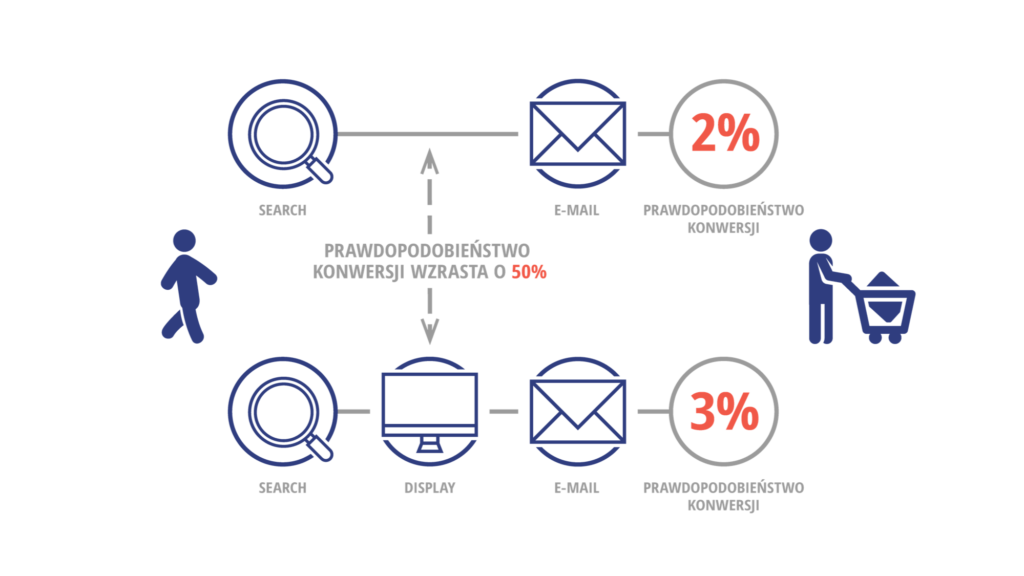
Grafika na podstawie materiałów Google
Szczegóły działania algorytmu nie są znane. Zresztą, algorytm ten z pewnością jest ustawicznie modyfikowany. W artykułach pomocy działanie tego algorytmu opisywane jest dość enigmatycznie, a podawane tam informacje ulegają stosunkowo częstym zmianom. Google wspomina o wykorzystywaniu takich metod, jak wartość Shapleya, łańcuchy Markowa i wnioskowanie bayesowskie.
W Google Analytics w raporcie ścieżek konwersji w sekcji Reklama możemy zobaczyć, jak wygląda podział konwersji pomiędzy poszczególne interakcje na danej ścieżce:
Czy model data-driven jest najlepszy?
Jak się wydaje, reklamodawcy oczekują od modelu data-driven, by dokonał przypisania konwersji do źródeł ruchu w sposób najbardziej sprawiedliwy i odwzorowujący wkład poszczególnych kanałów we wzrost konwersji.
Taka atrybucja będzie wskazówką do podejmowania decyzji o alokacji budżetu, zarówno tych podejmowanych przez marketera, jak i przez algorytm optymalizujący kampanie (np. smart bidding w Google Ads).
Aby to było możliwe, algorytmy te muszą być zasilane informacjami o inkrementalnym wkładzie poszczególnych kampanii w wynik, czyli o różnicę między wynikami sprzedaży, gdy kampania jest prowadzona, a wynikami które byłyby osiągane, gdyby z tej kampanii zrezygnowano.
Największym problemem modeli algorytmicznych w obecnym kształcie jest to, że opierają się one o analizę korelacji między interakcjami a konwersjami. Tym samym jest podatny na wykrywanie pozornych korelacji i wyciąganie na ich podstawie wniosków.
Jeśli sparafrazować ilustrację opisującą zasadę działania algorytmu data-driven, można by było wyciągnąć wniosek, że obecność bocianów w pobliżu zwiększa dzietność, gdyż prawdopodobieństwo że dwojgu ludziom, którzy stworzą związek i znajdą lokum w ciągu najbliższego roku urodzi się dziecko jest 2%, ale jeśli w okolicy znajdują się bociany, to prawdopodobieństwo wynosi 3%.
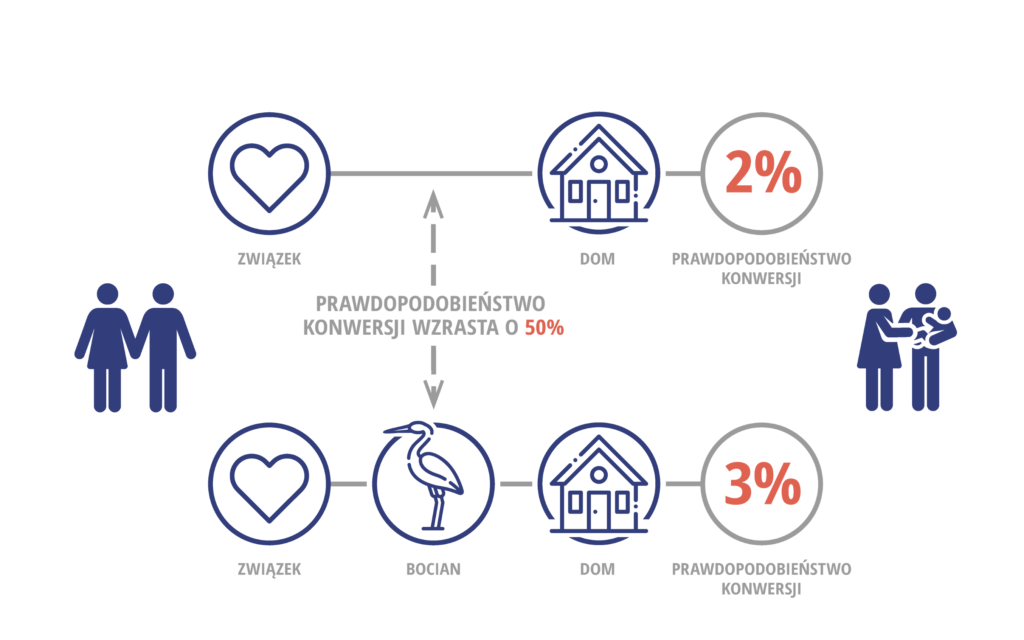
Faktycznie obserwowana różnica w dzietności dotyczyła miast i terenów wiejskich, na których znacznie częściej możemy obserwować bociany i gdzie w latach 90. XX wieku w Polsce obserwowano znacznie wyższą dzietność, niż w miastach (aktualnie te wskaźniki dla miast i wsi są zbliżone; w roku 2020 po raz pierwszy od wielu lat dzietność w miastach była wyższa niż na wsi).
Data-driven w wyszukiwarce
W materiałach Google znajdziemy również taki przykład opisujący działanie modelu data-driven w wynikach wyszukiwania:

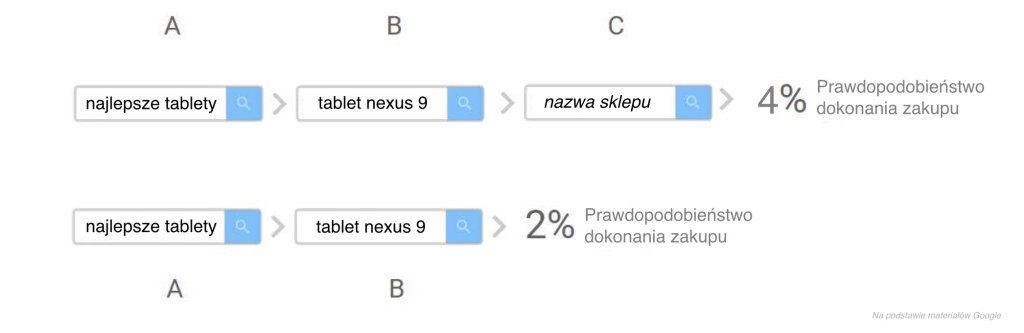
Porównując dane konwersji ścieżki ABC (na które wystąpiło kliknięcie A) ze ścieżką różniącą się tym, że brak na niej kliknięcia A, czyli ścieżką BC dochodzimy do wniosku, że ścieżka ABC ma o 50% większe prawdopodobieństwo konwersji (wzrost z 2% do 3%).
Mechanizm jest zrozumiały, użytkownik który szuka pomysłu na prezent najprawdopodobniej zamierza go kupić, więc na tle innych użytkowników, którzy szukają informacji o tabletach może on mieć większe prawdopodobieństwo konwersji.
Ale czy to właśnie kliknięcie w reklamę związaną ze słowem “gadżety na prezent” miało taki wpływ na zakup w naszym sklepie? Czy ten sam użytkownik, gdyby odwiedził naszą stronę po raz pierwszy szukając “najlepsze tablety” czy nawet dopiero szukając “tablet nexus 9” nie dokonałby również transakcji? Porównując ścieżki A > B > C oraz B > C, porównujemy użytkowników o których wiemy, że mają pilną intencję zakupową (szukają prezentu) z użytkownikami, którzy mają lub nie mają pełnej intencji zakupowej.
Zastanówmy się, co by było, gdyby nasz model analizował również kliknięcia reklam innych firm, nie tylko naszej. Załóżmy, że szukając “gadżetów na prezent” użytkownik wszedłby na stronę konkurencji, która również oferuje tablety, a następnie – zainspirowany – zacząłby szukać informacji o tabletach, by ostatecznie wybrać Nexusa 9.
Załóżmy, że osoby, które wcześniej odwiedziły stronę konkurencji przy wyszukiwaniu słowa “gadżety na prezent” również mają większy współczynnik konwersji:

Grafika na podstawie materiałów Google
Czy również tutaj moglibyśmy uznać, że prawdopodobieństwo konwersji wzrasta (w tym przypadku nieco mniej, o 40%) i na podstawie tego przypisać udział w konwersji reklamie, za którą zapłaciła konkurencja? Czy będąc konsekwentnym, uznalibyśmy że opłacałoby się dotowanie reklam konkurencji?
Wyszukiwanie marki a model data-driven
Jak opisane ograniczenia mogą wpływać na skuteczność działania modelu opartego o dane? Wyobraźmy sobie, że analizujemy zachowanie użytkowników naszego przykładu, którzy ostatecznie kupili tablet.
Widzimy, że wyszukiwali oni “najlepsze tablety” oraz “tablet nexus 9”, po czym zachowywali się w następujący sposób, że 20% z nich kupiło tablet od razu, a pozostali postanowili porównać oferty, po czym:
- 40% porównało oferty i kupiło u nas po wyszukiwaniu nazwy naszego sklepu
- 40% porównało oferty i kupiło u konkurencji
Użytkownicy, którzy postanowili wrócić, wchodzili na stronę przez reklamę, która wyświetliła się przy wyszukiwaniu nazwy sklepu, ale gdyby się nie wyświetliła, to wchodziliby przez link w bezpłatnych wynikach wyszukiwania który obecnie wyświetla się pod reklamą.
Z punktu widzenia ścieżek konwersji widzimy, że użytkownicy, którzy kliknęli w reklamę związaną z nazwą sklepu mieli dwa razy wyższy współczynnik konwersji niż ci, którzy jej nie kliknęli:
Faktycznie jednak, gdybyśmy reklamy na słowa nazwy sklepu wyłączyli, łączna liczba konwersji by się nie zmieniła istotnie, gdyż użytkownicy zamierzający kupić u nas tablet weszliby przez wyniki organiczne, a skoro tak, to atrybucja reklam związanych z nazwą sklepu jest zerowa.
W praktyce algortym potrafi tego nie zauważać i czasem robi coś wręcz przeciwnego, uznając że to właśnie reklama na własną nazwę jest kluczowa do zbudowania intencji zakupu:

Inną interakcją, która wynika z intencji zakupowej będzie też każda reklama remarketingowa. Jej wyświetlenie jest wynikiem zainteresowania, a pewna część użytkowników kupiłaby również, gdyby reklama nie została im wyświetlona.
Korelacja a przyczynowość
Problem, który napotykają algorytmy atrybucji data-driven takie, jak w analytics, wynika z niemożliwości określenia przyczynowości wyłącznie na podstawie obserwacji danych, Tymczasem może się zdarzyć, że niektóre interakcje nie są przyczyną pojawienia się intencji zakupowej, ale raczej jej skutkiem.
Na rysunku poniżej mamy następującą sytuację: Interakcja 1 (np. reklama w social media) spowodowała, że użytkownik zainteresował się naszą ofertą i postanowił z niej skorzystać. Interakcja 2 (np. kliknięcie naszej reklamy po wyszukaniu nazwy naszej firmy) była skutkiem zainteresowania, a jej wpływ na wzrost tego zainteresowania i dokonanie zakupu był znikomy (reprezentuje to cienka strzałka na diagramie prowadząca od interakcji 2 do zakupu).
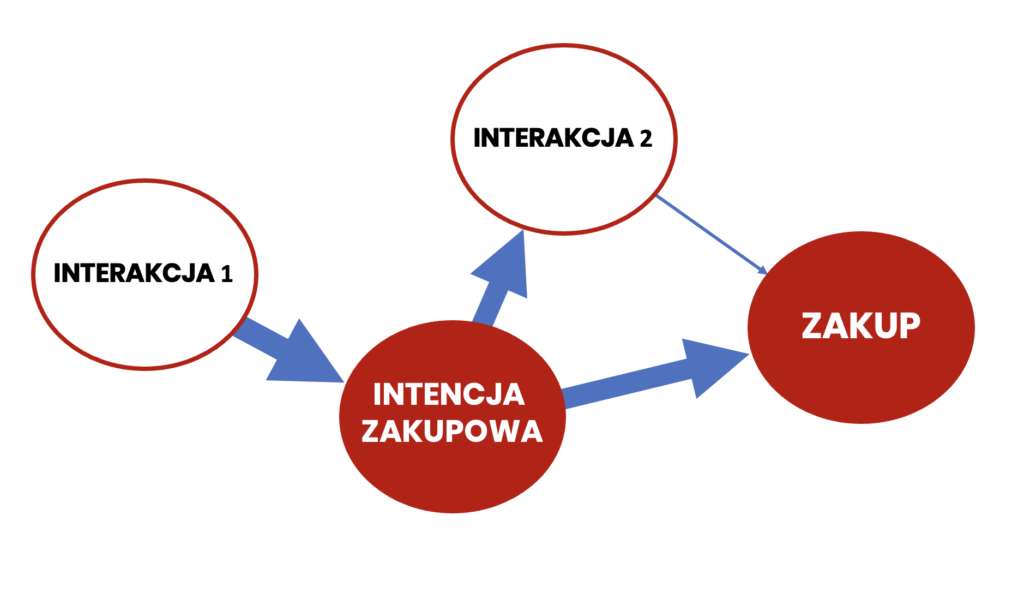
System śledzenia konwersji widzi następujące dane:
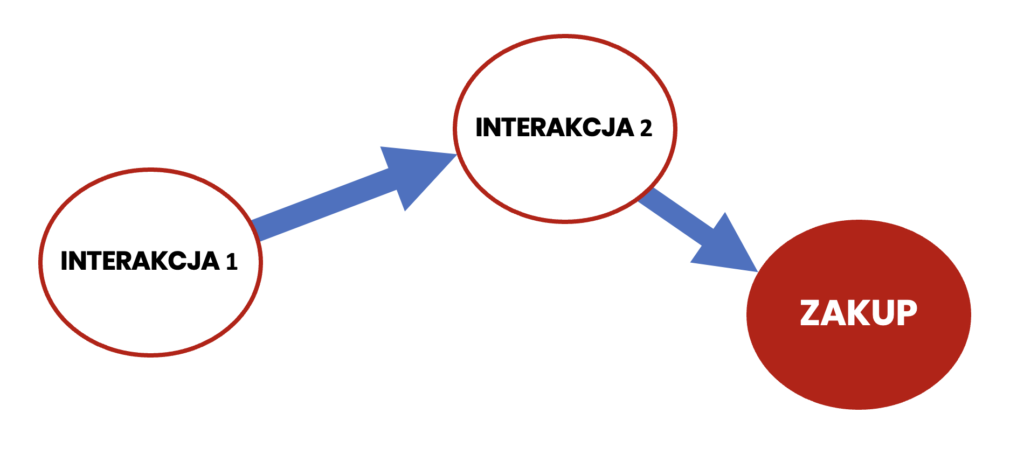
Z tych danych nie da się odczytać, że interakcja 2 faktycznie na konwersję wpływu nie miała. Z kolei ścieżki, na których jest wyłącznie interakcja 1 mogą konwertować znacznie rzadziej, ale będzie to oznaczało, że reklama 1 nie zaciekawiła tych użytkowników i w związku z tym interakcji 2 nie było.
Algorytm widząc, że głównie po integracji 2 dochodzi do konwersji, może interpretować to wręcz jako wskazanie, że to reklama 1 jest bezużyteczna.
Z tych powodów na podstawie samej korelacji między kliknięciem określonych reklam a konwersją nie możemy jednoznacznie wyciągać wniosków o istnieniu związku przyczynowo-skutkowego między nimi, ani oceniać jego siły.
Jak mierzyć wpływ reklam na wzrost sprzedaży?
Ludzie od wieków obserwowali, że słońce wschodzi wkrótce po tym, jak zapieje kogut. Czy w związku z tym wyciągnęliśmy wniosek, że pianie koguta wywołuje wschód słońca? Raczej nie. Wydaje się, że ludzie wiedzieli o tym jeszcze zanim poznali zasady rządzące ruchem planet. Wystarczył tu prosty eksperyment: po tym, jak kogut wylądował w garnku, słońce dalej wschodziło.
Aby określić związek przyczynowy i zmierzyć jego istotność, nie wystarczy obserwacja prawdopodobieństw warunkowych (np. prawdopodobieństwo konwersji pod warunkiem, że reklama została kliknięta vs. prawdopodobieństwo konwersji gdy kliknięcia nie było).
Chcąc zweryfikować hipotezę o przyczynowości, nie wystarczy sama obserwacja zjawisk: musimy dokonać ingerencji i w sposób sztuczny usunąć czynnik, który podejrzewamy o bycie przyczyną obserwowanych skutków, a następnie obserwować, jak to wpłynie na obserwowany wynik.
Dlatego jedynym sposobem, by zmierzyć oddziaływanie reklam, jest przeprowadzenie testu z grupą kontrolną, w którym w okresie testu grupie testowej nie będzie wyświetlana określona reklama.
W tym celu musimy zablokować wyświetlenie reklamy części użytkowników z grupy docelowej, którzy w normalnych warunkach by tę reklamę zobaczyli. Taki eksperyment nazywany jest czasem testem conversion lift lub pomiarem przyrostu konwersji:
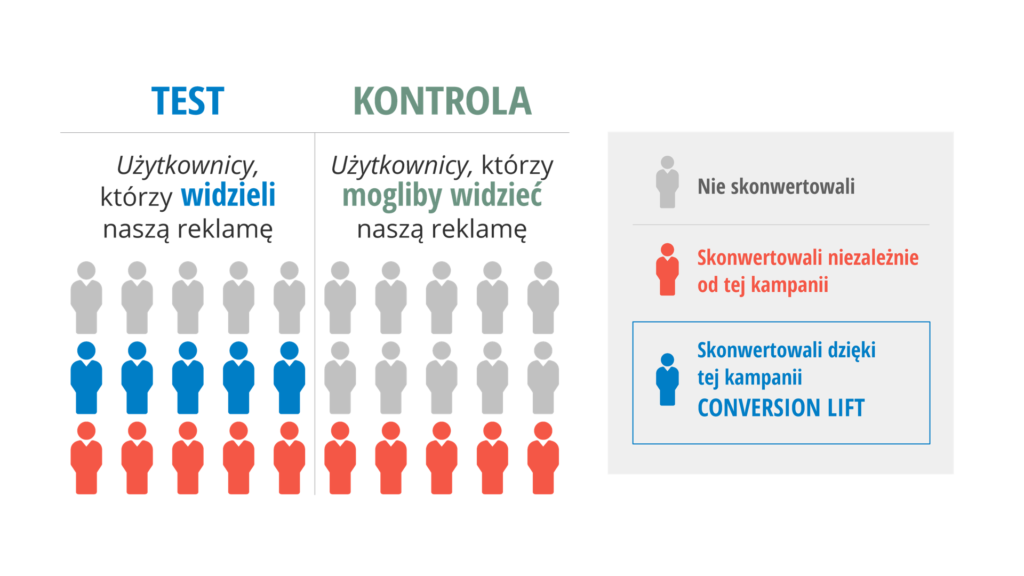
Porównując różnicę konwersji między osobami, które reklamę widziały, a tymi osobami z grupy docelowej, którym wyświetlenie zostało zablokowane, można oszacować generowany przyrost konwersji.
Dopóki algorytmiczne modele atrybucji nie zaczną weryfikować obserwowanych korelacji właśnie takimi randomizowanymi testami z grupą kontrolną, będą one podatne na tego rodzaju błędy.
Conversion lift – case study
Metodę conversion lift wykorzystaliśmy u jednego z naszych klientów. Rumuńskie biuro podróży Vola.ro przeprowadziło kampanię YouTube promującą niskie ceny biletów w styczniu. Reklama przekonywała, że jest to najlepszy moment na zakup biletu, ponieważ statystyki wskazują, że w tym czasie ich ceny są najkorzystniejsze.
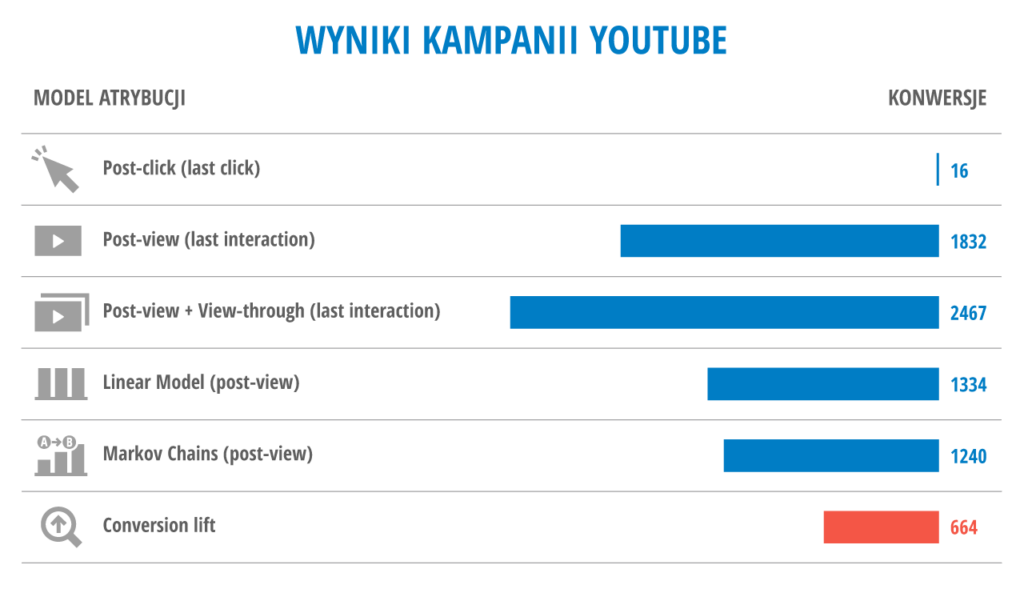
- Kampania uzyskała 17 mln* wyświetleń i współczynnik oglądalności na poziomie 47%
- Kampania wygenerowała 1832 konwersje po obejrzeniu reklamy
- Dodatkowo odnotowano 635 konwersji wśród użytkowników, którzy pominęli lub przerwali oglądanie reklamy
- Konwersji po kliknięciu było jedynie 16 (wg danych Google Analytics)
W zestawieniu z kosztami kampanii efekt post-click jest absolutnie niezadowalający. Konwersji post-view było bardzo dużo, ale biorąc pod uwagę kilkumilionowy zasięg kampanii, możemy oczekiwać, że dotarła ona do innych użytkowników na ścieżce konwersji, którzy mieli interakcje z reklamami w wyszukiwarce, na Facebooku lub w sieci reklamowej – w tym również z remarketingiem. Tylko 4% użytkowników, którzy dokonali konwersji z udziałem kampanii YouTube na ścieżce, nie miało na niej innych interakcji.
Czy w takim razie mogło być tak, że konwersje te uzyskano głównie dzięki pozostałym działaniom, a większość z tych klientów dokonałaby zakupu również bez kampanii YouTube? Odpowiedź na to pytanie mógł dać jedynie eksperyment conversion lift. Został on wykonany z wykorzystaniem 30% grupy kontrolnej, a wyniki zostały znormalizowane do 50% dla zapewnienia porównywalności:
- W grupie testowej odnotowano 2495 konwersji
- W grupie kontrolnej zarejestrowano 1831 konwersji
- Różnica to 664 konwersje
O tyle właśnie zwiększyła się sprzedaż dzięki inwestycji w tę kampanię YouTube.
Dla porównania, dokonano również analizy stosując różne modele atrybucji, w tym model oparty o łańcuchy Markowa.
Trudności w wykorzystaniu pomiarów przyrostu w modelach algorytmicznych
Jedną z największych przeszkód jest konieczność zaingerowania w wyświetlanie reklamy. By to zrobić, algorytm atrybucji (np. ten w Google Analytics) musiałby zablokować wyświetlanie reklam (np. Google Ads) części grupy docelowej. Mógłby to być np. test geo lift oparty o geolokalizację, gdzie grupą kontrolną byliby odbiorcy z określonego regionu.
Obecnie połączenie między Google Ads i Analytics jest wykorzystywane do raportowania Google Ads w Analytics oraz do zasilania Google Ads segmentami odbiorców z Analytics lub odczytanymi konwersjami. Mówimy tu o wzajemnym udostępnianiu danych.
Sterowanie przez Analytics wyświetlaniem reklam w Google Ads byłoby daleko idącym krokiem, choć technicznie wydaje się to możliwe. Tyle że Google Ads to nie jedyne źródło konwersji.
Tymczasem sytuacja się istotnie komplikuje, gdy chcielibyśmy to zastosować do innych kanałów, np. google / organic, bo to by oznaczało, że algorytm Analytics wpływałby na wyniki wyszukiwania.
A co w przypadku reklam na Facebooku lub organicznego ruchu z social media? Wizja, w której Meta pozwala algorytmowi Analytics ingerować w działanie algorytmu Facebooka nie wydaje się być realistyczna w najbliższej przyszłości.
Znacznie bardziej prawdopodobne jest, że algorytmy data-driven zaczną wykorzystywać eksperymenty z grupą kontrolną wewnątrz samych systemów reklamowych. Prawdopodobnie byłaby to dodatkowa opcja do zaznaczenia, w której reklamodawca zgodzi się na ograniczanie wyświetlania reklam pewnej części grupy docelowej.
Aktualnie (styczeń 2024) wydaje się to być dość odległą perspektywą, choć zarówno Google, jak i Meta wspominają coraz częściej o wykorzystywaniu danych z randomizowanych kontrolowanych eksperymentów w zasilaniu mechanizmów atrybucji data-driven w procesie uczenia algorytmów.
Następny artykuł (cz. 10): Wartość Shapleya
Warto przeczytać: Przewodnik po atrybucji w Google Analytics


